Data Engineering Evolution and Fundamentals
- Evolution of Data Engineering
- Early Days:
- Data engineers were originally software engineers focused on building software applications.
- Data generated by these applications was seen as a byproduct or “exhaust,” useful mainly for troubleshooting or monitoring.
- Shift in Perspective:
- Organizations began to recognize the intrinsic value of data as its volume and variety grew.
- Software engineers started building systems specifically for data ingestion, storage, transformation, and serving.
- Emergence of Data Engineering:
- Data engineering became a central function in organizations.
- The role of a data engineer was born to focus on managing data systems and pipelines.
- Definition of Data Engineering
- Core Definition:
- Data engineering involves developing, implementing, and maintaining systems that take raw data and produce high-quality, consistent information for downstream use cases like analysis and machine learning.
- Key Components:
- Data engineering sits at the intersection of:
- Security
- Data Management
- DataOps
- Data Architecture
- Orchestration
- Software Engineering
- Data engineering sits at the intersection of:
- Data Engineering Life Cycle
- Stages of the Life Cycle:
- Data Generation: Data is created by source systems (e.g., software applications, user-generated data, sensors).
- Ingestion: Data is collected from source systems.
- Transformation: Data is processed and transformed into a usable format.
- Storage: Data is stored, often spanning across ingestion, transformation, and serving stages.
- Serving: Data is made available for end-use cases.
- End Use Cases:
- Analytics, machine learning, and Reverse ETL (sending processed data back to source systems for additional value).
- Data Pipeline:
- A combination of architecture, systems, and processes that move data through the stages of the life cycle.
- Undercurrents of Data Engineering
- Undercurrents:
- These are overarching themes that span the entire data engineering life cycle:
- Security: Ensuring data is protected.
- Data Management: Organizing and maintaining data.
- DataOps: Streamlining data operations.
- Data Architecture: Designing data systems.
- Orchestration: Coordinating data workflows.
- Software Engineering: Building and maintaining data systems.
- These are overarching themes that span the entire data engineering life cycle:
- Relevance:
- Each undercurrent is relevant to all stages of the data engineering life cycle.
- Holistic Approach to Data Engineering
- Focus on Value:
- Data engineers should think holistically about the life cycle and undercurrents to deliver real value to the organization.
- Stakeholder Needs:
- Transforming stakeholder needs into system requirements is key to providing value.
History and Evolution of Data Engineering
- Data is Everywhere
- Definition of Data:
- Data comprises the building blocks of information.
- It can take many forms: words, numbers, photons, wind, etc.
- Recording Data: Data can be recorded as memories, writings, or digitally (e.g., videos, computer files).
- Digital Data: “Data” refers to digitally recorded data that can be stored on computers or transmitted over the internet.
- The Birth of Digital Data
- 1960s: The advent of computers led to the creation of the first computerized databases.
- 1970s: Relational databases emerged.
- IBM developed SQL (Structured Query Language).
- 1980s: Bill Inmon developed the first data warehouse to support analytical decision-making.
- 1990s:
- Growth of data systems led to the need for dedicated tools and pipelines for reporting and business intelligence.
- Ralph Kimball and Bill Inmon developed data modeling approaches for analytics.
- The internet went mainstream, leading to the rise of web-first companies like Amazon.
- Backend systems (servers, databases, storage) emerged to support web applications.
- The Big Data Era
- Early 2000s:
- After the dotcom bust, companies like Yahoo, Google, and Amazon faced an explosion of data.
- Traditional relational databases and data warehouses couldn’t handle the scale.
- Definition of Big Data:
- Extremely large datasets analyzed computationally to reveal patterns, trends, and associations.
- Characterized by the 3 Vs:
- Velocity: High speed of data generation.
- Variety: Diverse types of data.
- Volume: Large amounts of data.
- 2004: Google published the MapReduce paper, a scalable data processing paradigm.
- 2006: Yahoo developed and open-sourced Apache Hadoop, a revolutionary big data tool.
- Impact of Hadoop:
- Drew software engineers to large-scale data problems.
- Marked the beginning of the big data engineer role.
- The Rise of Cloud Computing
- Amazon Web Services (AWS):
- Created scalable solutions like EC2 (Elastic Cloud Compute), S3 (Simple Storage Service), and DynamoDB.
- AWS became the first popular public cloud, offering pay-as-you-go compute and storage.
- Google Cloud Platform and Microsoft Azure followed AWS.
- Impact of the Cloud:
- Revolutionized how software and data applications are developed and deployed.
- Enabled startups to access the same tools as top tech companies.
- Transition to Real-Time Data
- Shift from Batch to Event Streaming: Batch processing (analyzing data in chunks) gave way to event streaming (handling data as a continuous flow).
- Big Real-Time Data: Real-time data processing became a new focus.
- The Decline of “Big Data” as a Term
- Challenges of Big Data Tools:
- Managing tools like Hadoop required significant effort and cost.
- Big data engineers spent more time maintaining systems than delivering business value.
- Modern Data Engineering:
- Big data processing became more accessible.
- The term “big data” lost momentum as all companies, regardless of size, aimed to derive value from their data.
- Big data engineers are now simply data engineers.
- The Modern Data Ecosystem
- 2010s:
- Emergence of Cloud-first, open-source, and third-party products simplified working with data at scale.
- Data Engineering Today:
- Focuses on interoperability and connecting various technologies like Lego bricks.
- Data engineers are higher up the value chain, contributing directly to business goals.
- Opportunities for Data Engineers:
- Build scalable data systems using advanced tools.
- Contribute to the development of new technologies.
- Play a central role in achieving business strategy across industries.
Stakeholder Management in Data Engineering
Overview of the Data Engineer’s Role- A data engineer’s primary task is to:
- Acquire raw data.
- Transform it into a useful format.
- Make it available for downstream use cases.
- Success depends on understanding the needs of downstream data consumers to add value.
- Key Use Cases: Analytics and machine learning.
-
Potential Stakeholders:
- Business professionals (e.g., sales, marketing, executives)
- Data scientists, Machine learning engineers
- Analysts
-
Example: Supporting Business Analysts
- Analysts use SQL queries to generate dashboards, analyze trends, and predict metrics.
- Questions to consider for serving analysts:
- Query frequency for dashboard refreshes.
- Information needed in queries.
- Preprocessing needs like joins and aggregations for better performance.
- Latency tolerance (e.g., real-time data vs. hourly/daily updates).
- Data Definitions: Ensure alignment on metrics definitions (e.g., time zones for daily sales totals).
-
Key Considerations:
- Engage in company strategy to identify potential business value from data.
- Understand metrics and priorities important to downstream stakeholders.
-
Who Are They?
- Source system owners, often software engineers, responsible for systems generating raw data.
- These can be: Internal software engineers and external third-party system developers.
-
Data Engineer’s Role as a Consumer:
- Communicate with source system owners to understand:
- Volume, frequency, and format of raw data.
- Security and compliance considerations.
- Develop relationships to:
- Influence how data is served.
- Receive advance notice of changes (e.g., outages, schema updates).
- Communicate with source system owners to understand:
-
Dealing with External Systems:
- While external systems are often beyond direct control, connecting with their owners provides valuable insights into the source application.
-
Stakeholder Categories:
- Downstream stakeholders: Rely on transformed data to meet their goals.
- Upstream stakeholders: Provide the raw data needed for engineering pipelines.
-
Best Practices:
- Understand how upstream disruptions impact pipelines.
- Ensure data served downstream aligns with organizational goals and adds measurable value.
Business Value
Role of a Data Engineer- Key Responsibility: Transform raw data into useful data and make it accessible for downstream use cases.
-
Understanding Downstream Consumers:
- Engage deeply with downstream stakeholders to understand their requirements.
- Downstream consumers could include: Analysts, data scientists, machine learning engineers, and other decision-makers (e.g., salespeople, product managers, executives).
-
Tailoring Solutions:
- Example: Serving a business analyst:
- Understand query frequency, latency tolerance, and specific data definitions.
- Align on critical metrics like time zones or aggregation logic.
- Provide pre-aggregated data or optimized query structures for faster results.
- Example: Serving a business analyst:
-
Aligning with Business Goals:
- Be aware of the company’s strategy to align data solutions with organizational goals.
- Understand key business metrics and their significance.
-
Downstream Stakeholders:
- Value comes from enabling stakeholders to meet their objectives (e.g., trend analysis, dashboard creation, predictions).
- Addressing stakeholders’ requirements enhances data usability and business impact.
-
Upstream Stakeholders:
- Collaborate with software engineers or third-party system developers to:
- Understand source data formats, volumes, and frequencies.
- Plan for potential data flow disruptions, schema changes, or security compliance.
- Maintain open communication for proactive issue resolution.
- Collaborate with software engineers or third-party system developers to:
-
Two-Way Interaction:
- Downstream stakeholders rely on you for valuable data delivery.
- You depend on upstream systems for accurate, consistent raw data.
- Core Principle: Success as a data engineer is tied to delivering measurable business value.
-
Expert Insights:
- Advice from Bill Inman:
- Focus on projects that bring tangible business value rather than chasing the latest technologies.
- Align technical efforts with areas that impact revenue, cost savings, or efficiency.
- Advice from Bill Inman:
-
Perception of Value:
- Stakeholders judge value based on how solutions help achieve their goals:
- Increased revenue.
- Cost efficiency.
- Simplified workflows.
- Successful product launches.
- Stakeholders judge value based on how solutions help achieve their goals:
-
Managing Conflicting Needs:
- Stakeholder demands may exceed available resources or capacity.
- Prioritization of projects becomes crucial:
- Focus on feasible projects with high impact.
- Estimate timelines and resource requirements.
-
Strategic Decision-Making:
- Effective prioritization requires balancing stakeholder goals with organizational constraints.
System Requirements
-
Understand the Types of Requirements:
- Business Requirements: High-level organizational goals (e.g., increase revenue or grow user base).
- Stakeholder Requirements: Individual needs to accomplish tasks (e.g., accurate reports, anomaly detection).
- System Requirements:
- Functional Requirements: The “what” the system must do (e.g., data pipeline schedules).
- Non-Functional Requirements: The “how” the system operates (e.g., performance, scalability, and compliance).
-
The Requirement Gathering Process:
- Not Unique to Data Engineering:
- Commonly used in product development and management.
- The process involves understanding stakeholder needs and translating them into system requirements.
- Start with Stakeholder Conversations:
- Understand their roles, goals, and technical background.
- Identify how their work ties into broader business objectives.
- Translate Needs into Requirements:
- Break down broad goals into actionable system features.
- Include technical specifications and constraints (e.g., memory limits, budget).
- Steps in Requirements Gathering:
- Identify Business Goals: Understand the high-level objectives of the organization.
- Identify Stakeholders: Determine who will use or benefit from the data system.
- Understand Current Systems: Learn about existing systems and their limitations.
- Define Stakeholder Needs: Gather detailed requirements from stakeholders.
- Determine Functional and Non-Functional Requirements:
- Functional Requirements: What the system must do (e.g., generate reports, support queries).
- Non-Functional Requirements: How the system should perform (e.g., latency, scalability, security).
- Not Unique to Data Engineering:
- Anticipate Constraints: Address cost limitations and compliance with security and regulatory standards early in the planning process.
- Iterative Collaboration: Recognize stakeholders’ perspectives evolve, and refine requirements iteratively.
-
Skill Development:
- Enhance communication skills for varied technical audiences.
- Develop systems thinking to bridge abstract goals with concrete implementations.
- Prepare for Stakeholder Meetings:
- Research the business area or department’s goals.
- Prepare questions to uncover unspoken needs.
- Draft Requirement Templates: Create templates for functional and non-functional requirements to organize your findings.
- Review with Stakeholders: Regularly validate the gathered requirements to ensure alignment with expectations.
- Bridge Communication Gaps: Use visualization tools (e.g., workflows, diagrams) to clarify complex system ideas to less technical stakeholders.
- Balance Prioritization: Evaluate feasibility based on impact and resources while ensuring essential requirements are met.
Thinking Like a Data Engineer
- Thinking Like a Data Engineer: A Framework
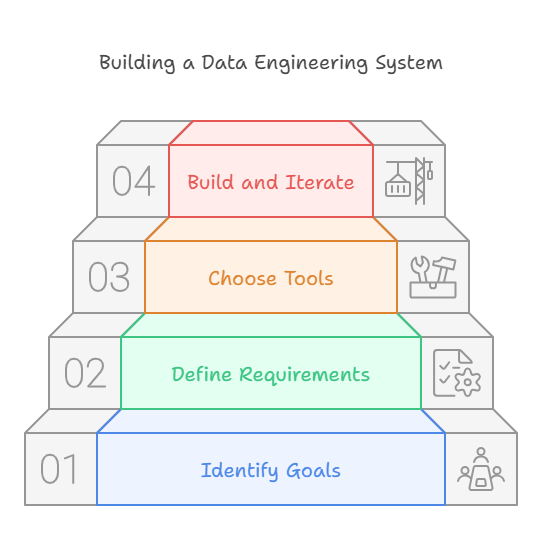
- Stage 1: Identify Business Goals and Stakeholder Needs:
- Objective: Understand the business goals and how stakeholder needs align with them.
- Key Actions:
- Clarify high-level business goals.
- Identify stakeholders and their needs.
- Conduct conversations with stakeholders to understand their pain points and expectations.
- Ask stakeholders what actions they plan to take with the data products (e.g., dashboards, machine learning models).
- Stage 2: Define Functional and Non-Functional Requirements:
- Objective: Translate stakeholder needs into clear system requirements.
- Key Actions:
- Document functional requirements (what the system must do).
- Define non-functional requirements (how the system should perform).
- Confirm with stakeholders that the documented requirements will meet their needs.
- Stage 3: Choose Tools and Technologies:
- Objective: Select the best tools and technologies to meet the requirements.
- Key Actions:
- Identify tools and technologies that can meet the requirements.
- Evaluate trade-offs between tools (e.g., cost, scalability, ease of use).
- Perform a cost-benefit analysis (e.g., licensing fees, cloud resource costs).
- Build a prototype to test the chosen tools and technologies.
- Stage 4: Build, Deploy, and Iterate:
- Objective: Implement the system and continuously improve it.
- Key Actions:
- Build and deploy the data system.
- Continuously monitor and evaluate system performance.
- Iterate on the system to adapt to changing stakeholder needs or new technologies.
- Key Considerations in the Framework
- Prototyping/POC:
- Before fully building the system, create a prototype to test whether it meets stakeholder needs.
- Iterate on the prototype to ensure the final system will deliver value.
- Evolution of Data Systems:
- Data systems are not static; they must evolve as business goals and stakeholder needs change.
- Regularly communicate with stakeholders to ensure the system continues to meet their needs.
- Cyclical Process: The framework is not linear but cyclical. As needs and technologies change, revisit earlier stages to update the system.
- Prototyping/POC: