Overview
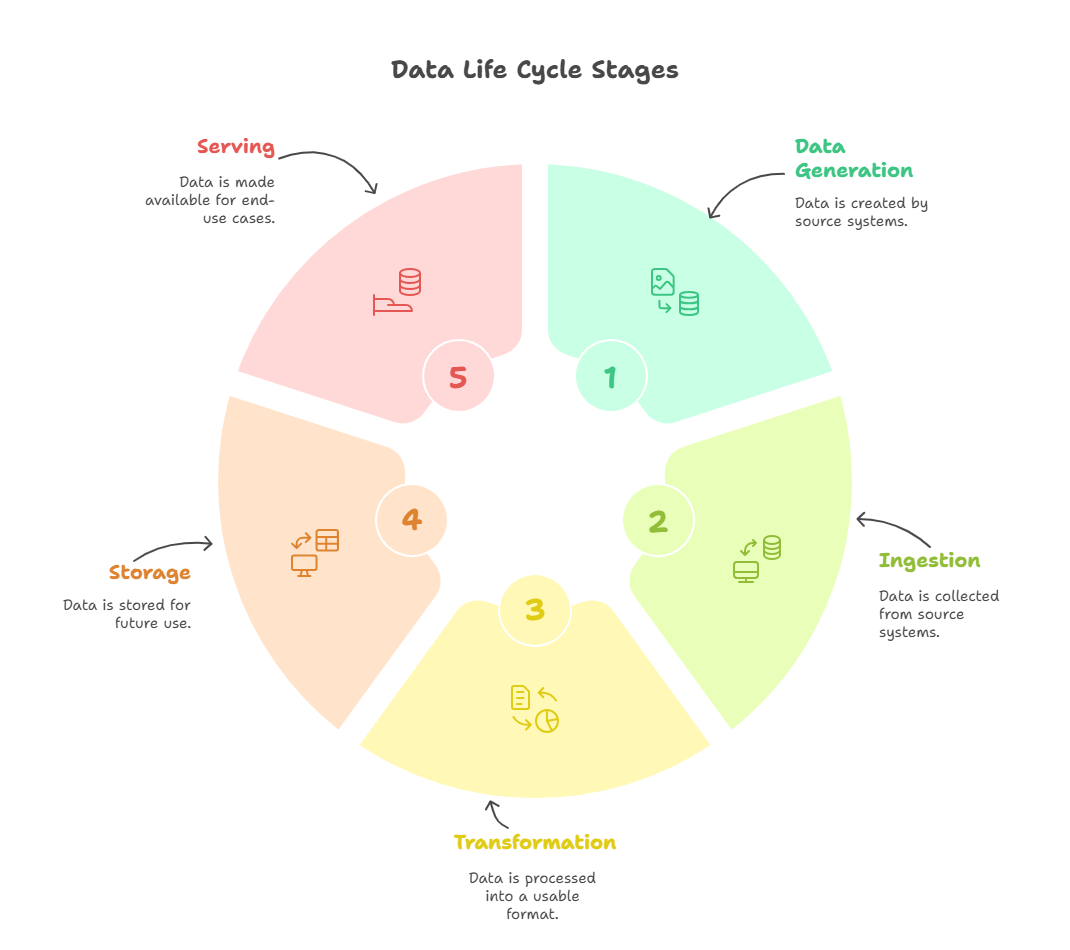
- Lifecycle Stages:
- Data Generation: Happens before the data engineer’s role begins.
- Ingestion: Moving raw data into the pipeline.
- Transformation: Turning raw data into something useful.
- Storage: Storing data for further use.
- Serving: Making data available for downstream use cases (e.g., analytics, machine learning).
Data Generation and Source Systems
- Role of Data Engineer: Consume data from various sources (e.g., databases, APIs, IoT devices).
- Common Source Systems:
- Databases: Relational (SQL) or NoSQL (key-value, document stores).
- Files: Text, audio, video, etc.
- APIs: Fetch data in formats like JSON or XML.
- Data Sharing Platforms: Internal or third-party platforms.
- IoT Devices: Real-time data streams (e.g., GPS trackers).
- Challenges:
- Source systems are often maintained by other teams (e.g., software engineers).
- Data formats or schemas may change unexpectedly, disrupting pipelines.
- Key Takeaway: Build strong relationships with source system owners to understand data generation and anticipate changes.
Ingestion
- Definition: Moving raw data from source systems into the pipeline for processing.
- Ingestion Patterns:
- Batch Ingestion:
- Data is processed in chunks (e.g., hourly, daily).
- Common for analytics and machine learning.
- Streaming Ingestion:
- Data is processed in near real-time (e.g., less than one second delay).
- Requires tools like event streaming platforms or message queues.
- Batch Ingestion:
- Trade-offs:
- Batch: Simpler, cost-effective, but slower.
- Streaming: Faster, but more complex and expensive.
- Key Considerations:
- Use streaming only when justified by a business use case.
- Most pipelines combine batch and streaming components.
- Change Data Capture (CDC): Trigger ingestion based on data changes in source systems.
- Push vs. Pull: Decide whether the source system pushes data or you pull it.
Storage
- Importance: Storage systems determine the function, performance, and limitations of data pipelines.
- Storage Hierarchy:
- Raw Ingredients:
- Physical: Magnetic disks, SSDs, RAM.
- Non-physical: Networking, CPU, serialization, compression, caching.
- Storage Systems:
- Databases, object storage (e.g., Amazon S3), streaming storage.
- Storage Abstractions:
- Data warehouses, data lakes, data lakehouses.
- Raw Ingredients:
- Key Considerations:
- Cost: Magnetic disks are cheaper than SSDs or RAM.
- Performance: RAM is faster but volatile and expensive.
- Scalability: Distributed storage across clusters and data centers.
- Common Mistakes:
- Poorly designed ingestion (e.g., direct row inserts) can be slow and costly.
- Use bulk ingestion for large datasets to save time and money.
Queries, Modeling, and Transformation
- Transformation: The stage where raw data is turned into something useful.
- Components:
- Queries:
- Retrieve data from storage systems (e.g., using SQL).
- Poorly written queries can lead to performance issues or row explosion.
- Data Modeling:
- Represent data in a way that reflects real-world relationships.
- Normalization vs. Denormalization: Balance complexity and query efficiency.
- Transformation:
- Manipulate, enhance, and prepare data for downstream use.
- Examples: Adding timestamps, mapping data types, aggregating data.
- Queries:
- Key Considerations:
- Work with stakeholders to understand business goals and terminology.
- Ensure data models align with organizational workflows and logic.
Serving Data
- Purpose: Make data available for downstream use cases to extract business value.
- Common Use Cases:
- Analytics:
- Business Intelligence (BI): Historical and current data for insights (e.g., dashboards, reports).
- Operational Analytics: Real-time data for immediate action (e.g., monitoring website performance).
- Embedded Analytics: Customer-facing analytics (e.g., bank spending dashboards, smart thermostat apps).
- Machine Learning:
- Serve data for model training and real-time inference.
- Manage feature stores, metadata, and data lineage.
- Reverse ETL:
- Push transformed data, analytics, or ML outputs back into source systems (e.g., CRM systems).
- Analytics:
- Key Considerations:
- Tailor data serving to the specific needs of stakeholders.
- Ensure data is accessible, reliable, and timely.
Key Takeaways
- Data Engineering Lifecycle:
- Starts with data generation and ends with serving data for downstream use cases.
- Key stages: Ingestion, Transformation, Storage, and Serving.
- Undercurrents: Security, Data Management, DataOps, Data Architecture, Orchestration, and Software Engineering underpin all stages of the lifecycle.
- Stakeholder Collaboration: Work closely with source system owners and downstream users to ensure data pipelines meet business needs.
- Ingestion Patterns: Choose between batch and streaming ingestion based on use case requirements.
- Storage Optimization: Understand the hierarchy of storage systems and choose the right abstraction (e.g., data warehouse, data lake).
- Transformation: Add value by querying, modeling, and transforming raw data into useful formats.
- Serving Data: Deliver data for analytics, machine learning, and reverse ETL to drive business value.
Source: DeepLearning.ai data engineering course.